Quickstart: Launch an Inference Workload¶
Introduction¶
Machine learning (ML) inference refers to the process of using a trained machine learning model to make predictions or generate outputs based on new, unseen data. After a model has been trained on a dataset, inference involves applying this model to new examples to produce results such as classifications, predictions, or other types of insights.
The quickstart below shows an inference server running the model and an inference client.
There are various ways to submit a Workload:
- Run:ai command-line interface (CLI)
- Run:ai user interface
- Run:ai API
At this time, Inference services cannot be created via the CLI. The CLI can be used for creating a client to query the inference service.
Prerequisites¶
To complete this Quickstart, the Infrastructure Administrator will need to install some optional inference prerequisites as described here.
To complete this Quickstart, the Platform Administrator will need to provide you with:
- ML Engineer access to Project in Run:ai named "team-a"
- The project should be assigned a quota of at least 1 GPU.
- The URL of the Run:ai Console. E.g. https://acme.run.ai.
As described, the inference client can be created via CLI. To perform this, you will need to have the Run:ai CLI installed on your machine. There are two available CLI variants:
- The older V1 CLI. See installation here
- A newer V2 CLI, supported with clusters of version 2.18 and up. See installation here
Step by Step Walkthrough¶
Login¶
Run runai login and enter your credentials.
Run runai login and enter your credentials.
Browse to the provided Run:ai user interface and log in with your credentials.
To use the API, you will need to obtain a token. Please follow the api authentication article.
Create an Inference Server Environment¶
To complete this Quickstart via the UI, you will need to create a new Inference Server Environment asset.
This is a one-time step for all Inference workloads using the same image.
Under Environments Select NEW ENVIRONMENT. Then select:
- A default (cluster) scope.
- Use the environment name
inference-server. - The image
runai.jfrog.io/demo/example-triton-server. - Under
type of workloadselectinference. - Under
endpointset the container port as8000which is the port that the triton server is using.
Run an Inference Workload¶
Not available right now.
Not available right now.
- In the Run:ai UI select Workloads
- Select New Workload and then Inference
- You should already have
ClusterandProjectselected. Enterinference-server-1as the name and press CONTINUE. - Under
Environment, selectinference-server. - Under
Compute Resource, selecthalf-gpu. - Under `Replica autoscaling, select a minimum of 1 and a maximum of 2.
- Under
conditions for a new replicaselectConcurrencyand set the value as 3. - Set the
scale to zerooption to5 minutes - Select CREATE INFERENCE.
Note
For more information on submitting Workloads and creating Assets via the user interface, see Workload documentation.
curl -L 'https://<COMPANY-URL>/api/v1/workloads/inferences' \ # (1)
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <TOKEN>' \ # (2)
-d '{
"name": "inference-server-1",
"projectId": "<PROJECT-ID>", '\ # (3)
"clusterId": "<CLUSTER-UUID>", \ # (4)
"spec": {
"image": "runai.jfrog.io/demo/example-triton-server",
"servingPort": {
"protocol": "http",
"container": 8000
},
"autoscaling": {
"minReplicas": 1,
"maxReplicas": 2,
"metric": "concurrency",
"metricThreshold": 3,
"scaleToZeroRetentionSeconds": 300
},
"compute": {
"cpuCoreRequest": 0.1,
"gpuRequestType": "portion",
"cpuMemoryRequest": "100M",
"gpuDevicesRequest": 1,
"gpuPortionRequest": 0.5
}
}
}'
<COMPANY-URL>is the link to the Run:ai user interface. For exampleacme.run.ai<TOKEN>is an API access token. see above on how to obtain a valid token.<PROJECT-ID>is the the ID of theteam-aProject. You can get the Project ID via the Get Projects API<CLUSTER-UUID>is the unique identifier of the Cluster. You can get the Cluster UUID by adding the "Cluster ID" column to the Clusters view.
Note
- The above API snippet will only work with Run:ai clusters of 2.18 and above.
- For more information on the Inference Submit API see API Documentation
This would start a triton inference server with a maximum of 2 instances, each instance consumes half a GPU.
Query the Inference Server¶
You can use the Run:ai Triton demo client to send requests to the server
Find the Inference Server Endpoint¶
- Under
Workloads, selectColumnson the top right. Add the columnConnections. - See the connections of the
inference-server-1workload:
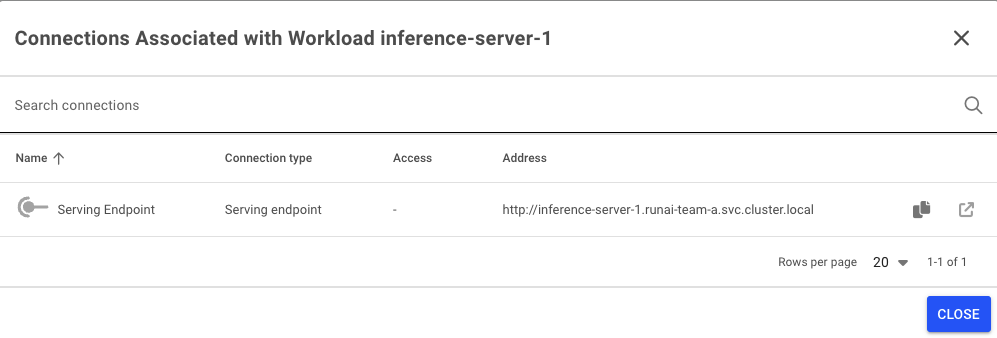
- Copy the inference endpoint URL.
Open a terminal and run:
Open a terminal and run:
- In the Run:ai UI select Workloads
- Select New Workload and then Training
- You should already have
Cluster,Projectand astart from scratchTemplateselected. Enterinference-client-1as the name and press CONTINUE. - Select NEW ENVIRONMENT. Enter
inference-clientas the name andrunai.jfrog.io/demo/example-triton-clientas the image. Select CREATE ENVIRONMENT. - When the previous screen comes up, select
cpu-onlyunder the Compute resource. - Under
runtime settingsenter the command asperf_analyzerand arguments-m inception_graphdef -p 3600000 -u <INFERENCE-ENDPOINT>(replace inference endpoint with the above URL). - Select CREATE TRAINING.
In the user interface, under inference-server-1, go to the Metrics tab and watch as the various GPU and inference metrics graphs rise.
Stop Workload¶
Run the following:
Not available right now
Not available right now
Select the two workloads and press DELETE.