Quickstart: Launch Distributed Training Workloads¶
Introduction¶
Distributed Training is the ability to split the training of a model among multiple processors. Each processor is called a worker. Worker nodes work in parallel to speed up model training. There is also a master which coordinates the workers.
Distributed Training should not be confused with multi-GPU training. Multi-GPU training is the allocation of more than a single GPU to your workload which runs on a single container.
Getting distributed training to work is more complex than a single-container training as it requires syncing of data and timing between the different workers. However, it is often a necessity when multi-GPU training no longer applies; typically when you require more GPUs than exist on a single node. Several Deep Learning frameworks support distributed training. This example will focus on PyTorch.
Run:ai provides the ability to run, manage, and view distributed training workloads. The following is a Quickstart document for such a scenario.
There are various ways to submit a distributed training Workload:
- Run:ai command-line interface (CLI)
- Run:ai user interface
- Run:ai API
Prerequisites¶
To complete this Quickstart, the Infrastructure Administrator will need to install the optional Kubeflow Training Operator as described here
To complete this Quickstart, the Platform Administrator will need to provide you with:
- Researcher access to Project in Run:ai named "team-a"
- The project should be assigned a quota of at least 1 GPU.
- A URL of the Run:ai Console. E.g. https://acme.run.ai.
To complete this Quickstart via the CLI, you will need to have the Run:ai CLI installed on your machine. There are two available CLI variants:
- The older V1 CLI. See installation here
- A newer V2 CLI, supported with clusters of version 2.18 and up. See installation here
Step by Step Walkthrough¶
Login¶
Run runai login and enter your credentials.
Run runai login and enter your credentials.
Browse to the provided Run:ai user interface and log in with your credentials.
To use the API, you will need to obtain a token. Please follow the api authentication article.
Run a Distributed Training Workload¶
Open a terminal and run:
runai config project team-a
runai submit-dist pytorch dist-train1 --workers=2 -g 0.1 \
-i gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0
Note
For more information on the workload submit command, see cli documentation.
Open a terminal and run:
runai project set team-a
runai distributed submit dist-train1 --framework PyTorch \
-i gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0 --workers 2
--gpu-request-type portion --gpu-portion-request 0.1 --gpu-devices-request 1 --cpu-memory-request 100M
Note
For more information on the training submit command, see cli documentation.
- In the Run:ai UI select Workloads
- Select New Workload and then Training
- You should already have
Cluster,Projectand astart from scratchTemplateselected. - Under
Workload architectureselectDistributedand choosePyTorch. Set the distributed training configuration toWorkers & master. - Enter
train1as the name and press CONTINUE. - Select NEW ENVIRONMENT. Enter
pytorch-dtas the name andgcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0as the image. Then select CREATE ENVIRONMENT. - When the previous screen comes up, under
Compute resourceenter 2 workers and selectsmall-fractionas the Compute resource. - Select CONTINUE and then CREATE TRAINING.
Note
For more information on submitting Workloads and creating Assets via the user interface, see Workload documentation.
curl -L 'https://<COMPANY-URL>/api/v1/workloads/distributed' \ # (1)
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <TOKEN>' \ # (2)
-d '{
"name": "dist-train1",
"projectId": "<PROJECT-ID>", '\ # (3)
"clusterId": "<CLUSTER-UUID>", \ # (4)
"spec": {
"compute": {
"cpuCoreRequest": 0.1,
"gpuRequestType": "portion",
"cpuMemoryRequest": "100M",
"gpuDevicesRequest": 1,
"gpuPortionRequest": 0.1
},
"image": "gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0",
"numWorkers": 2, \ # (5)
"distributedFramework": "PyTorch" \ # (6)
}
}'
<COMPANY-URL>is the link to the Run:ai user interface. For exampleacme.run.ai<TOKEN>is an API access token. see above on how to obtain a valid token.<PROJECT-ID>is the the ID of theteam-aProject. You can get the Project ID via the Get Projects API<CLUSTER-UUID>is the unique identifier of the Cluster. You can get the Cluster UUID by adding the "Cluster ID" column to the Clusters view.- Use 2 workers.
- Use PyTorch training operator
Note
- The above API snippet will only work with Run:ai clusters of 2.18 and above. For older clusters, use, the now deprecated Cluster API.
- For more information on the Distributed Training Submit API see API Documentation
This would start a distributed training Workload for team-a. The Workload will have one master and two workers. We named the Workload dist-train1
List Workloads¶
Follow up on the Workload's progress by running:

The result:
- Open the Run:ai user interface.
- Under "Workloads" you can view the new Training Workload:

- Select the
0/2under Running/Requested Pods and watch the worker pod status:
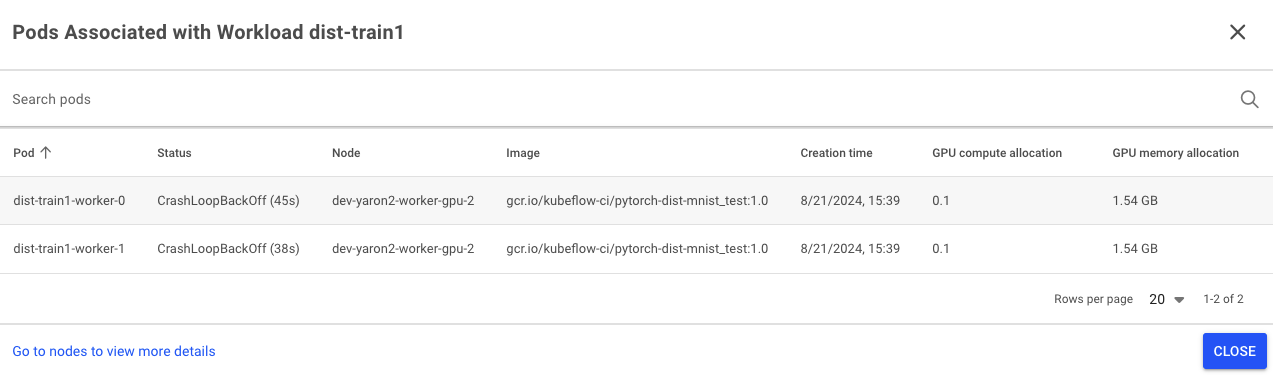
Select the dist-train1 workload and press Show Details to see the Workload details
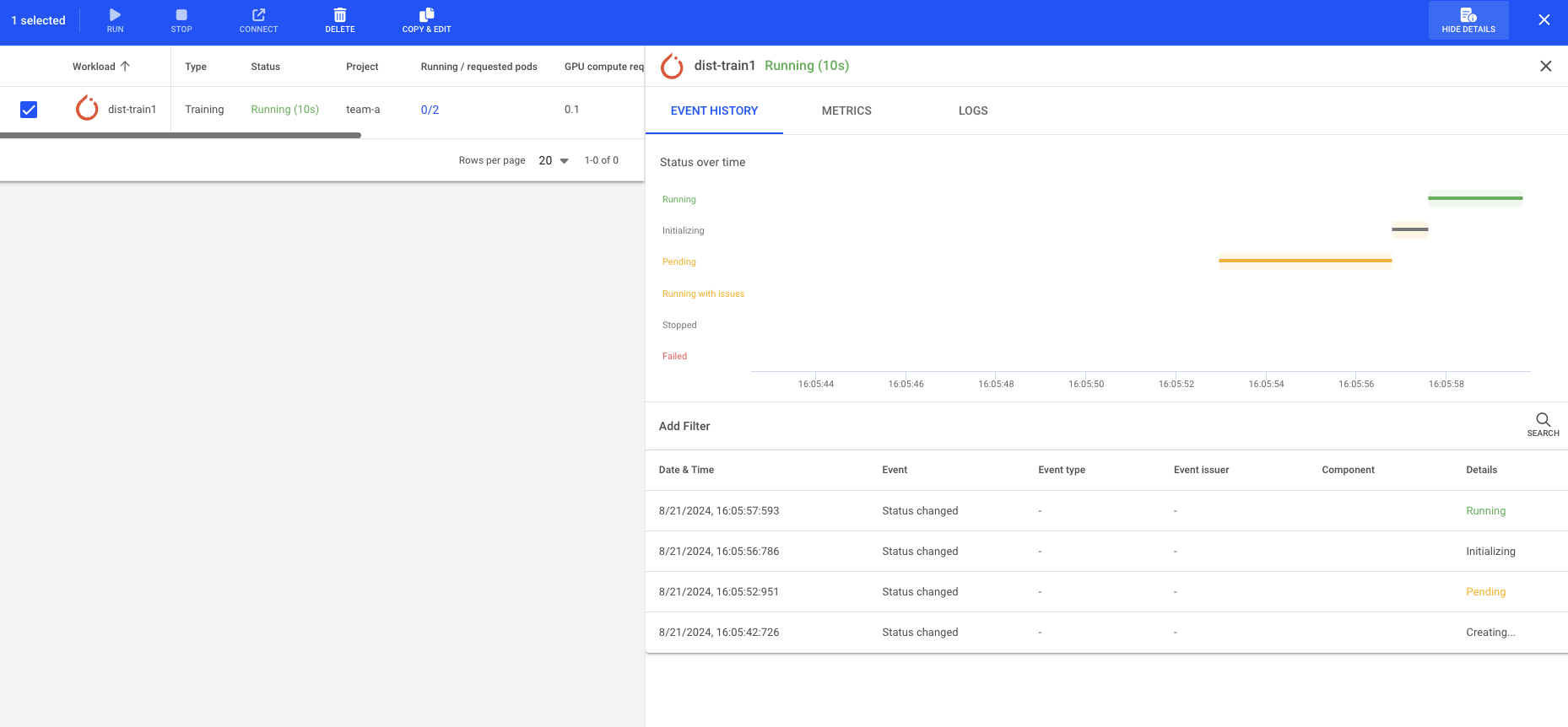
Describe Workload¶
The Run:ai scheduler ensures that all pods can run together. You can see the list of workers as well as the main "launcher" pod by running:
View Logs¶
Run the following:
Get the name of the worker pods from the above describe command, then run:
(where dist-train1-worker-0 is the name of the first worker)
You should see a log of a running container
Get the name of the worker pods from the above describe command, then run:
(where dist-train1-worker-0 is the name of the first worker)
You should see a log of a running container:
Select the Workload, and press Show Details. Under Logs you can select each of the workers and see the logs emitted from the container
Stop Workload¶
Run the following:
This would stop the training workload. You can verify this by listing training workloads again.