Job Statuses
Introduction¶
The runai submit function and its sibling the runai submit-dist mpi function submit Run:ai Jobs for execution.
A Job has a status. Once a Job is submitted it goes through several statuses before ending in an End State. Most of these statuses originate in the underlying Kubernetes infrastructure, but some are Run:ai-specific.
The purpose of this document is to explain these statuses as well as the lifecycle of a Job.
Successful Flow¶
A regular, training Job that has no errors and executes without preemption would go through the following statuses:

- Pending - the Job is waiting to be scheduled.
- ContainerCreating - the Job has been scheduled, the Job docker image is now downloading.
- Running - the Job is now executing.
- Succeeded - the Job has finished with exit code 0 (success).
The Job can be preempted, in which case it can go through other statuses:
- Terminating - the Job is now being preempted.
- Pending - the Job is waiting in queue again to receive resources.
An interactive Job, by definition, needs to be closed by the Researcher and will thus never reach the Succeeded status. Rather, it would be moved by the Researcher to status Deleted.
For a further explanation of the additional statuses, see the table below.
Error flow¶
A regular, training Job may encounter an error inside the running process (exit code is non-zero). In which case the following will happen:
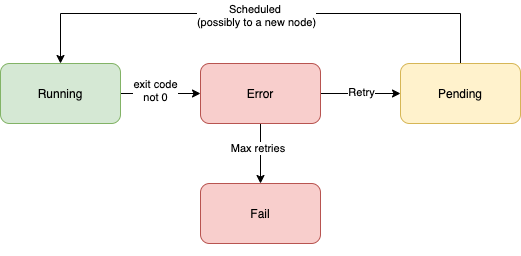
The Job enters an Error status and then immediately tries to reschedule itself for another attempted run. The reschedule can happen on another node in the system. After a specified number of retries, the Job will enter a final status of Fail
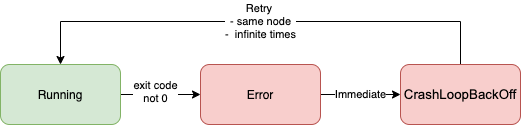
An interactive Job, enters an Error status and then moves immediately to CrashLoopBackOff trying to reschedule itself. The reschedule attempt has no 'back-off' limit and will continue to retry indefinitely
Jobs may be submitted with an image that cannot be downloaded. There are special statuses for such Jobs. See table below
Status Table¶
Below is a list of statuses. For each status the list shows:
-
Name
-
End State - this status is the final status in the lifecycle of the Job
-
Resource Allocation - when the Job is in this status, does the system allocate resources to it
-
Description
-
Color - Status color as can be seen in the Run:ai User Interface Job list
| Status | End State | Resource Allocation | Description | Color |
| Running | | Yes | Job is running successfully | |
| Terminating | | Yes | Pod is being evicted at the moment (e.g. due to an over-quota allocation, the reason will be written once eviction finishes). A new pod will be created shortly | |
| ContainerCreating | | Yes | Image is being pulled from registry. | |
| Pending | | - | Job is pending. Possible reasons: - Not enough resources - Waiting in Queue (over-quota etc). | |
| Succeeded | Yes | - | An Unattended (training) Job has ran and finished successfully. | |
| Deleted | Yes | - | Job has been deleted. | |
| TimedOut | Yes | - | Interactive Job has reached the defined timeout of the project. | |
| Preempted | Yes | - | Interactive preemptible Job has been evicted. | |
| ContainerCannotRun | Yes | - | Container has failed to start running. This is typically a problem within the docker image itself. | |
| Error | | Yes for interactive only | The Job has returned an exit code different than zero. It is now waiting for another run attempt (retry). | |
| Fail | Yes | - | Job has failed after a number of retries (according to "--backoffLimit" field) and will not be trying again. | |
| CrashLoopBackOff | | Yes | Interactive Only: During backoff after Error, before a retry attempt to run pod on the same node. | |
| ErrImagePull, ImagePullBackOff | | Yes | Failing to retrieve docker image | |
| Unknown | Yes | - | The Run:ai Scheduler wasn't running when the Job has finished. | |
How to get more information¶
The system stores various events during the Job's lifecycle. These events can be helpful in diagnosing issues around Job scheduling. To view these events run:
runai describe job <workload-name>
Sometimes, useful information can be found by looking at logs emitted from the process running inside the container. For example, Jobs that have exited with an exit code different than zero may write an exit reason in this log. To see Job logs run:
runai logs <job-name>
Distributed Training (mpi) Jobs¶
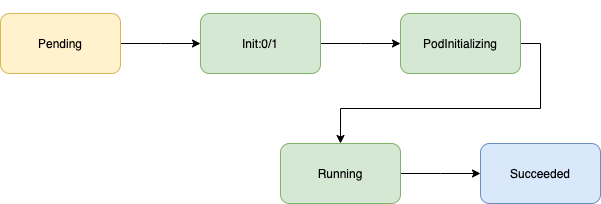
A distributed (mpi) Job, which has no errors will be slightly more complicated and has additional statuses associated with it.
-
Distributed Jobs start with an "init container" which sets the stage for a distributed run.
-
When the init container finishes, the main "launcher" container is created. The launcher is responsible for coordinating between the different workers
-
Workers run and do the actual work.
A successful flow of distribute training would look as:
Additional Statuses:
| Status | End State | Resource Allocation | Description | Color |
| Init:<number A>/<number B> | | Yes | The Pod has B Init Containers, and A have completed so far. | |
| PodInitializing | | Yes | The pod has finished executing Init Containers. The system is creating the main 'launcher' container | |
| Init:Error | | | An Init Container has failed to execute. | |
| Init:CrashLoopBackOff | | | An Init Container has failed repeatedly to execute | |