Prerequisites
Prerequisites in a Nutshell¶
The following is a checklist of the Run:ai prerequisites:
| Prerequisite | Details |
|---|---|
| Kubernetes | Verify certified vendor and correct version. |
| NVIDIA GPU Operator | Different Kubernetes flavors have slightly different setup instructions. Verify correct version. |
| Ingress Controller | Install and configure NGINX (some Kubernetes flavors have NGINX pre-installed). |
| Prometheus | Install Prometheus. |
| Trusted domain name | You must provide a trusted domain name. Accessible only inside the organization |
| (Optional) Distributed Training | Install Kubeflow Training Operator if required. |
| (Optional) Inference | Some third party software needs to be installed to use the Run:ai inference module. |
There are also specific hardware, operating system and network access requirements. A pre-install script is available to test if the prerequisites are met before installation.
Software Requirements¶
Operating System¶
- Run:ai will work on any Linux operating system that is supported by both Kubernetes and NVIDIA.
- An important highlight is that GKE (Google Kubernetes Engine) will only work with Ubuntu, as NVIDIA does not support the default Container-Optimized OS with Containerd image.
- Run:ai performs its internal tests on Ubuntu 20.04 and CoreOS for OpenShift.
Kubernetes¶
Run:ai requires Kubernetes. Run:ai is been certified with the following Kubernetes distributions:
| Kubernetes Distribution | Description | Installation Notes |
|---|---|---|
| Vanilla Kubernetes | Using no specific distribution but rather k8s vanilla installation | See instructions for a simple (non-production-ready) Kubernetes Installation script. |
| OCP | OpenShift Container Platform | The Run:ai operator is certified for OpenShift by Red Hat. |
| EKS | Amazon Elastic Kubernetes Service | |
| AKS | Azure Kubernetes Services | |
| GKE | Google Kubernetes Engine | |
| RKE | Rancher Kubernetes Engine | When installing Run:ai, select On Premise |
| BCM | NVIDIA Base Command Manager | In addition, NVIDIA DGX comes bundled with Run:ai |
Run:ai has been tested with the following Kubernetes distributions. Please contact Run:ai Customer Support for up to date certification details:
| Kubernetes Distribution | Description | Installation Notes |
|---|---|---|
| Ezmeral | HPE Ezmeral Container Platform | See Run:ai at Ezmeral marketplace |
| Tanzu | VMWare Kubernetes | Tanzu supports containerd rather than docker. See the NVIDIA prerequisites below as well as cluster customization for changes required for containerd |
Following is a Kubernetes support matrix for the latest Run:ai releases:
| Run:ai version | Supported Kubernetes versions | Supported OpenShift versions |
|---|---|---|
| Run:ai 2.9 | 1.21 through 1.26 | 4.8 through 4.11 |
| Run:ai 2.10 | 1.21 through 1.26 (see note below) | 4.8 through 4.11 |
| Run:ai 2.13 | 1.23 through 1.28 (see note below) | 4.10 through 4.13 |
| Run:ai 2.15 | 1.25 through 1.28 | 4.11 through 4.13 |
| Run:ai 2.16 | 1.26 through 1.28 | 4.11 through 4.14 |
| Run:ai 2.17 | 1.27 through 1.29 | 4.12 through 4.15 |
For information on supported versions of managed Kubernetes, it's important to consult the release notes provided by your Kubernetes service provider. Within these notes, you can confirm the specific version of the underlying Kubernetes platform supported by the provider, ensuring compatibility with Run:ai.
For an up-to-date end-of-life statement of Kubernetes see Kubernetes Release History.
Note
Run:ai allows scheduling of Jobs with PVCs. See for example the command-line interface flag --pvc-new. A Job scheduled with a PVC based on a specific type of storage class (a storage class with the property volumeBindingMode equals to WaitForFirstConsumer) will not work on Kubernetes 1.23 or lower.
Pod Security Admission¶
Run:ai version 2.15 and above supports restricted policy for Pod Security Admission (PSA) on OpenShift only. Other Kubernetes distributions are only supported with Privileged policy.
For Run:ai on OpenShift to run with PSA restricted policy:
- The
runainamespace should still be marked asprivilegedas described in Pod Security Admission. Specifically, label the namespace with the following labels:
pod-security.kubernetes.io/audit=privileged
pod-security.kubernetes.io/enforce=privileged
pod-security.kubernetes.io/warn=privileged
- The workloads submitted through Run:ai should comply with the restrictions of PSA
restrictedpolicy, which are dropping all Linux capabilities and settingrunAsNonRoottotrue. This can be done and enforced using Policies.
NVIDIA¶
Run:ai has been certified on NVIDIA GPU Operator 22.9 to 24.6. Older versions (1.10 and 1.11) have a documented NVIDIA issue.
Follow the Getting Started guide to install the NVIDIA GPU Operator, or see the distribution-specific instructions below:
- When setting up EKS, do not install the NVIDIA device plug-in (as we want the NVIDIA GPU Operator to install it instead). When using the eksctl tool to create an AWS EKS cluster, use the flag
--install-nvidia-plugin=falseto disable this install. - Follow the Getting Started guide to install the NVIDIA GPU Operator. For GPU nodes, EKS uses an AMI which already contains the NVIDIA drivers. As such, you must use the GPU Operator flags:
--set driver.enabled=false.
Create the gpu-operator namespace by running
Before installing the GPU Operator you must create the following file:
apiVersion: v1
kind: ResourceQuota
metadata:
name: gcp-critical-pods
namespace: gpu-operator
spec:
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values:
- system-node-critical
- system-cluster-critical
Then run: kubectl apply -f resourcequota.yaml
Important
- Run:ai on GKE has only been tested with GPU Operator version 22.9 and up.
- The above only works for Run:ai 2.7.16 and above.
- Follow the Getting Started guide to install the NVIDIA GPU Operator.
- Make sure to specify the
CONTAINERD_CONFIGoption exactly with the value specified in the document/var/lib/rancher/rke2/agent/etc/containerd/config.toml.tmpleven though the file may not exist in your system.
Notes
- Use the default namespace
gpu-operator. Otherwise, you must specify the target namespace using the flagrunai-operator.config.nvidiaDcgmExporter.namespaceas described in customized cluster installation. - NVIDIA drivers may already be installed on the nodes. In such cases, use the NVIDIA GPU Operator flags
--set driver.enabled=false. DGX OS is one such example as it comes bundled with NVIDIA Drivers. - To use Dynamic MIG, the GPU Operator must be installed with the flag
mig.strategy=mixed. If the GPU Operator is already installed, edit the clusterPolicy by runningkubectl patch clusterPolicy cluster-policy -n gpu-operator --type=merge -p '{"spec":{"mig":{"strategy": "mixed"}}} - For troubleshooting information, see the NVIDIA GPU Operator Troubleshooting Guide.
Ingress Controller¶
Run:ai requires an ingress controller as a prerequisite. The Run:ai cluster installation configures one or more ingress objects on top of the controller.
There are many ways to install and configure an ingress controller and configuration is environment-dependent. A simple solution is to install & configure *NGINX_:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm upgrade -i nginx-ingress ingress-nginx/ingress-nginx \
--namespace nginx-ingress --create-namespace \
--set controller.kind=DaemonSet \
--set controller.service.externalIPs="{<INTERNAL-IP>,<EXTERNAL-IP>}" # (1)
- External and internal IP of one of the nodes
RKE and RKE2 come pre-installed with NGINX. No further action needs to be taken.
For support of ingress controllers different than NGINX please contact Run:ai customer support.
Note
In a self-hosted installation, the typical scenario is to install the first Run:ai cluster on the same Kubernetes cluster as the control plane. In this case, there is no need to install an ingress controller as it is pre-installed by the control plane.
Cluster URL¶
The Run:ai cluster creation wizard requires a domain name (FQDN) to the Kubernetes cluster as well as a trusted certificate for that domain. The domain name needs to be accessible inside the organization only.
Use an HTTPS-based domain (e.g. https://my-cluster.com) as the cluster URL. Make sure that the DNS is configured with the cluster IP.
In addition, to configure HTTPS for your URL, you must create a TLS secret named runai-cluster-domain-tls-secret in the runai namespace. The secret should contain a trusted certificate for the domain:
kubectl create ns runai
kubectl create secret tls runai-cluster-domain-tls-secret -n runai \
--cert /path/to/fullchain.pem \ # (1)
--key /path/to/private.pem # (2)
- The domain's cert (public key).
- The domain's private key.
For more information on how to create a TLS secret see: https://kubernetes.io/docs/concepts/configuration/secret/#tls-secrets.
Note
In a self-hosted installation, the typical scenario is to install the first Run:ai cluster on the same Kubernetes cluster as the control plane. In this case, the cluster URL need not be provided as it will be the same as the control-plane URL.
Prometheus¶
If not already installed on your cluster, install the full kube-prometheus-stack through the Prometheus community Operator.
Note
- If Prometheus has been installed on the cluster in the past, even if it was uninstalled (such as when upgrading from Run:ai 2.8 or lower), you will need to update Prometheus CRDs as described here. For more information on the Prometheus bug see here.
- If you are running Kubernetes 1.21, you must install a Prometheus stack version of 45.23.0 or lower. Use the
--versionflag below. Alternatively, use Helm version 3.12 or later. For more information on the related Prometheus bug see here
Then install the Prometheus stack by running:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus prometheus-community/kube-prometheus-stack \
-n monitoring --create-namespace --set grafana.enabled=false # (1)
- The Grafana component is not required for Run:ai.
Notes
- In an air-gapped environment, if needed, configure the
global.imageRegistryvalue to reference the local registry hosting the Prometheus images. - For troubleshooting information, see the Prometheus Troubleshooting Guide.
Optional Software Requirements¶
The following software enables specific features of Run:ai
Distributed Training¶
Distributed training allows the Researcher to train models over multiple nodes. Run:ai supports the following distributed training frameworks:
- TensorFlow
- PyTorch
- XGBoost
- MPI
All are part of the Kubeflow Training Operator. Run:ai supports Training Operator version 1.7 and up. To install run:
The Kuberflow Training Operator is packaged with MPI version 1.0 which is not supported by Run:ai. You need to separately install MPI v2beta1:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/v0.4.0/deploy/v2beta1/mpi-operator.yaml
Important
If you need both MPI and one of the other frameworks, follow the following process:
- Install the training operator as above.
- Disable MPI in the Training operator by running:
- Run:
kubectl delete crd mpijobs.kubeflow.org. - Install MPI v2beta1 as above.
Inference¶
To use the Run:ai inference module you must pre-install Knative Serving. Follow the instructions here to install. Run:ai is certified on Knative 1.4 to 1.12.
Post-install, you must configure Knative to use the Run:ai scheduler and allow pod affinity, by running:
kubectl patch configmap/config-features \
--namespace knative-serving \
--type merge \
--patch '{"data":{"kubernetes.podspec-schedulername":"enabled","kubernetes.podspec-affinity":"enabled","kubernetes.podspec-tolerations":"enabled","kubernetes.podspec-volumes-emptydir":"enabled","kubernetes.podspec-securitycontext":"enabled","kubernetes.podspec-persistent-volume-claim":"enabled","kubernetes.podspec-persistent-volume-write":"enabled","multi-container":"enabled","kubernetes.podspec-init-containers":"enabled"}}'
Inference Autoscaling¶
Run:ai allows to autoscale a deployment using the following metrics:
- Throughput (requests/second)
- Concurrency
Accessing Inference from outside the Cluster¶
Inference workloads will typically be accessed by consumers residing outside the cluster. You will hence want to provide consumers with a URL to access the workload. The URL can be found in the Run:ai user interface under the deployment screen (alternatively, run kubectl get ksvc -n <project-namespace>).
However, for the URL to be accessible outside the cluster you must configure your DNS as described here.
Alternative Configuration
When the above DNS configuration is not possible, you can manually add the Host header to the REST request as follows:
- Get an
<external-ip>by runningkubectl get service -n kourier-system kourier. If you have been using istio during Run:ai installation, run:kubectl -n istio-system get service istio-ingressgatewayinstead. - Send a request to your workload by using the external ip, and place the workload url as a
Hostheader. For example
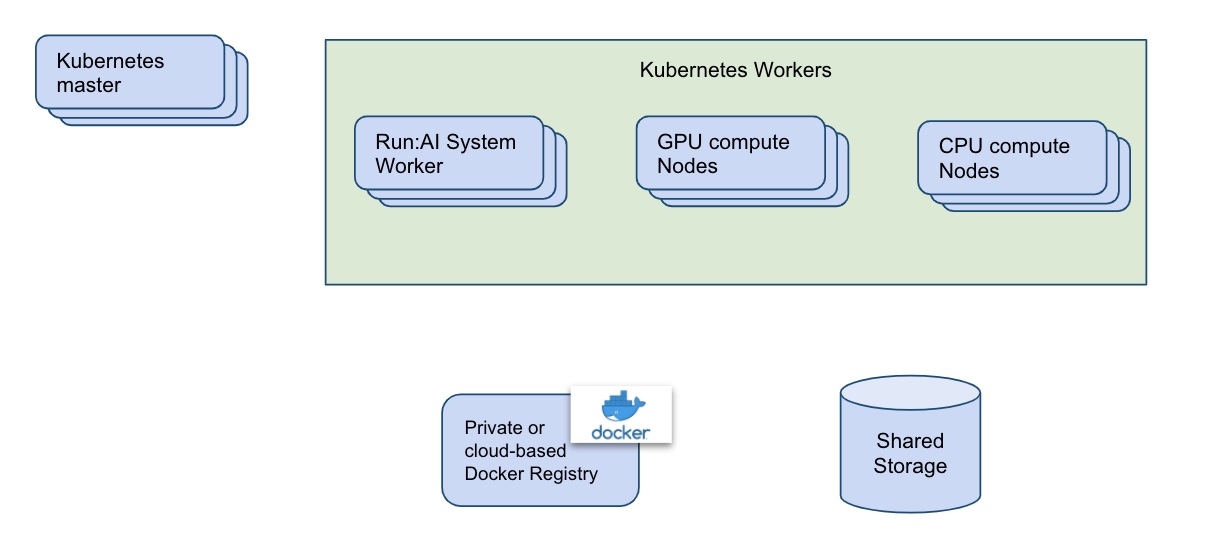
Hardware Requirements¶
(see picture below)
-
(Production only) Run:ai System Nodes: To reduce downtime and save CPU cycles on expensive GPU Machines, we recommend that production deployments will contain two or more worker machines, designated for Run:ai Software. The nodes do not have to be dedicated to Run:ai, but for Run:ai purposes we would need:
-
8 CPUs
- 16GB of RAM
-
50GB of Disk space
-
Shared data volume: Run:ai uses Kubernetes to abstract away the machine on which a container is running:
-
Researcher containers: The Researcher's containers need to be able to access data from any machine in a uniform way, to access training data and code as well as save checkpoints, weights, and other machine-learning-related artifacts.
-
The Run:ai system needs to save data on a storage device that is not dependent on a specific node.
Typically, this is achieved via Kubernetes Storage class based on Network File Storage (NFS) or Network-attached storage (NAS).
-
Docker Registry: With Run:ai, Workloads are based on Docker images. For container images to run on any machine, these images must be downloaded from a docker registry rather than reside on the local machine (though this also is possible. You can use a public registry such as docker hub or set up a local registry on-prem (preferably on a dedicated machine). Run:ai can assist with setting up the repository.
-
Kubernetes: Production Kubernetes installation requires separate nodes for the Kubernetes master. For more details see your specific Kubernetes distribution documentation.
User requirements¶
Usage of containers and images: The individual Researcher's work must be based on container images.
Network Access Requirements¶
Internal networking: Kubernetes networking is an add-on rather than a core part of Kubernetes. Different add-ons have different network requirements. You should consult the documentation of the specific add-on on which ports to open. It is however important to note that unless special provisions are made, Kubernetes assumes all cluster nodes can interconnect using all ports.
Outbound network: Run:ai user interface runs from the cloud. All container nodes must be able to connect to the Run:ai cloud. Inbound connectivity (connecting from the cloud into nodes) is not required. If outbound connectivity is limited, the following exceptions should be applied:
During Installation¶
Run:ai requires an installation over the Kubernetes cluster. The installation access the web to download various images and registries. Some organizations place limitations on what you can pull from the internet. The following list shows the various solution components and their origin:
| Name | Description | URLs | Ports |
|---|---|---|---|
| Run:ai Repository | Run:ai Helm Package Repository | runai.jfrog.io/ui/native/run-ai-charts | 443 |
| Docker Images Repository | Run:ai images | gcr.io/run-ai-prod | 443 |
| Docker Images Repository | Third party Images | hub.docker.com and quay.io | 443 |
| Run:ai | Run:ai Cloud instance | app.run.ai | 443 |
Post Installation¶
In addition, once running, Run:ai requires an outbound network connection to the following targets:
| Name | Description | URLs | Ports |
|---|---|---|---|
| Grafana | Grafana Metrics Server | prometheus-us-central1.grafana.net and runailabs.com | 443 |
| Run:ai | Run:ai Cloud instance | app.run.ai | 443 |
Network Proxy¶
If you are using a Proxy for outbound communication please contact Run:ai customer support
Pre-install Script¶
Once you believe that the Run:ai prerequisites are met, we highly recommend installing and running the Run:ai pre-install diagnostics script. The tool:
- Tests the below requirements as well as additional failure points related to Kubernetes, NVIDIA, storage, and networking.
- Looks at additional components installed and analyze their relevance to a successful Run:ai installation.
To use the script download the latest version of the script and run:
If the script shows warnings or errors, locate the file runai-preinstall-diagnostics.txt in the current directory and send it to Run:ai technical support.
For more information on the script including additional command-line flags, see here.